Recently I started reading "
High Performance Browser Networking", and If you ask me, I will say it's a masterpiece! Not just for developers, but also for SysAdmins and DevOps! This summary for first part of this great book, the first 4 chapters cover TCP, UDP, TLS, and networking essentials.
Actually, as a system administrator, I've seen a lot of developers do the same mistakes (specially Front-End developers), small mistakes lead to big performance issues! And those mistakes can be fixed with minimum efforts! So I really love this book slogan "
What every web developer should know about Networking and Browser Performance!"
This post summarize about 20,000 words in less than 2500 words! However, I'm highly recommend to read the book, it's
available online for free!
About The Book:

- Name: High Performance Browser Networking.
- Author: Ilya Grigorik - Web performance engineer and developer advocate on the Make The Web Fast team at Google.
- Description: How prepared are you to build fast and efficient web applications? This eloquent book provides what every web developer should know about the network, from fundamental limitations that affect performance to major innovations for building even more powerful browser applications - including HTTP 2.0 and XHR improvements, Server-Sent Events (SSE), WebSocket, and WebRTC.
Part1 - Networking 101 (CH 1-4)
Ch1. Primer on Latency and Bandwidth.
- Speed is a feature! faster websites lead to better engagement, better retention, higher conversions! Latency and bandwidth are the bottleneck here!
- Latency has a lot of components: Delay in propagation, transmission, processing, queuing. So the "Latency" == "all delays between any two sides".
- Even though we can reach maximum transfer speed using fiber optics but at the end, speed of light has limitations; which are distance and medium.
- Ironically, we get max speed across the oceans due to less latency, but in the "last mile" between you and your ISP there are a lot of deterioration in speed! That's due to routing and materials between you and your ISP.
- Bandwidth can do nothing with latency! Think in terms of a bigger hose on a far tank, water still needs to go all the way through the hose to reach you.
Ch2. Building Blocks of TCP.
- The Internet has two main protocols; IP (Internet Protocol) and TCP (Transmission Control Protocol). Their first appearance was in 1974 by Vint Cerf and Bob Kahn.
- HTTP -in practice- uses TCP whereas nothing can be done with latency itself, optimization and enhancements in TCP means faster HTTP.
- TCP Property number zero ... Three-way handshake! (SYN .. SYN ACK .. ACK).
The delay imposed by the three-way handshake makes new TCP connections expensive to create, and is one of the big reasons why connections reuse is a critical optimization for any application running over TCP.
- For the previous reason, a new mechanism has been developed "TCP Fast Open", which is:
An extension to speed up the opening of successive Transmission Control Protocol (TCP) connections between two endpoints. It works by using a TFO cookie (a TCP option), which is a cryptographic cookie stored on the client side and set upon the initial connection with the server - Wikipedia.
- When both ends have different bandwidth capacity, the end with bigger bandwidth may send too much data to other; which may not be able to process it. So, in early versions of TCP, there were multiple mechanisms to address this problem such as "Flow Control", "Congestion Control" and "Congestion Avoidance".
- Flow control is a mechanism to prevent the sender from overwhelming the receiver with data it may not be able to process - the receiver may be busy, under heavy load ... etc.
- To address this, every system has a default value for the size of the available buffer space to hold called "RWND" (Receive Window)
- RWND value is a part of every TCP connection so both sides can dynamically adjust data flow rate that fits each side (and when "RWND=0" this means this side can't get any more data).
- Flow control can prevent both sides from overwhelming each other, but has nothing to do with the network or any mediator between them.
- Slow-Start was created to address this issue using CWND (Congestion Window Size), CWND limits amount of data the receiver can have, so the server starts the connection with small amount of data and if there is no packet loss, it will double packet size till packet loss occurs. Then, the server will decrease the size of packets (actually, the server decreases CWND which in turn limits amount of data that is sent to receiver) and the process/it starts again.
- Slow-Start is very important factor in HTTP connections because we cannot use the full capacity of the link immediately no matter how large the available bandwidth is. And this is a big problem of HTTP connections due to the nature of many of HTTP connections being short and hasty unlike other large connections such as streaming download. So, a lot of web applications performance will be limited with slow-start!
- If there is a "slow-start" then of course there is "slow-start restart"! SSR is a mechanism which reset the CWND value when the connection becomes idle -even for a blink- so the connection will start again from CWND defaults. this option has bad effect for long-lived connections like HTTP keepalive so disable it.
To check and disable it on Linux do the following:
$> sysctl net.ipv4.tcp_slow_start_after_idle
$> sysctl -w net.ipv4.tcp_slow_start_after_idle=0
- Starting from Linux kernel 2.6.39 initial congestion window got a bigger value (Value of 10 segments - IW10), but there are more improvements in kernel 3.2+ as we shall see later.
- When slow-start hits bandwidth limits and packet loss occurs as mentioned before, there is another mechanism takes place called "Congestion Avoidance". Congestion Avoidance is a mechanism to minimize further loss.
- Congestion Avoidance is under heavy R&D, so you will find many variants and a lot of implementations.
Proportional Rate Reduction for TCP:
- Determining the optimal way to recover from packet loss is a nontrivial exercise: if you are too aggressive, then an intermittent lost packet will have significant impact on throughput of the entire connection, and if you don’t adjust quickly enough, then you will induce more packet loss!
- Proportional Rate Reduction (PRR) is a new algorithm specified by RFC 6937, whose goal is to improve the speed of recovery when a packet is lost. How much better is it? According to measurements done at Google, where the new algorithm was developed, it provides a 3–10% reduction in average latency for connections with packet loss.
- PRR is now the default congestion avoidance algorithm in Linux 3.2+ kernels another good reason to upgrade your servers!
- Congestion control and congestion avoidance are applied on local networks too! and can also be the bottleneck in those high speed LANs. so you need to take care about this point even in local networks.
- TCP provides an easy and reliable way to transfer data, but the core feature of TCP is its same weakness point, If one of the packets is lost enroute to the receiver, then all subsequent packets must be held in the receiver’s TCP buffer until the lost packet is retransmitted and arrives at the receiver’s and this effect is known as TCP head-of-line (HOL) blocking.
- TCP is a great protocol, but not every application needs its features, so don't use it unless you need its features because there’s no way to get some and leave out all the rest.
- Packet loss is an important part of how TCP works as we have seen before, so it's ok.
- TCP is a flexible protocol and appropriate for a lot of environments and scenarios, so for the same reason, the best way to optimize TCP is to tune it based on your environment and specific conditions (Web, wireless, LAN, WAN ... etc).
- Regardless environment, TCP has core principles and their implications remain unchanged.
- TCP three-way handshake introduces a full roundtrip of latency.
- TCP slow-start is applied to every new connection.
- TCP flow and congestion control regulate throughput of all connections.
- TCP throughput is regulated by current congestion window size.
- Before you do any optimization in TCP configuration, make sure to upgrade your server because, as mentioned before, there are a lot of enhancements already evolved and implemented.
Performance Checklist:
Optimizing TCP performance pays high dividends, regardless of the type of application, for every new connection to your servers. A short list to put on the agenda:
- Upgrade server kernel to latest version (Linux: 3.2+).
- Ensure that cwnd size is set to 10.
- Disable slow-start after idle.
- Ensure that window scaling is enabled.
- Eliminate redundant data transfers.
- Compress transferred data.
- Position servers closer to the user to reduce roundtrip times.
- Reuse established TCP connections whenever possible.
Ch3. Building Blocks of UDP.
- UDP (User Datagram Protocol) is one of popular protocols nowadays, and is always referred to as the opposite form of TCP, Not because of the features that it has, but the features that it doesn’t have It’s so popular that even its RFC (RFC 768) can be written on a napkin!
- The UDP protocol encapsulates user messages into its own packet structure, with only four additional fields 1. Source port 2. Destination port 3. Length of packet 4. Checksum (Actually; source port and the checksum fields are optional!!), and lack of other fields as in TCP results the following in UDP:
- No guarantee of message delivery.
- No guarantee of order of delivery.
- No connection state tracking.
- No congestion control.
- We can summaries the difference between TCP and UDP at the level of message/information as follows:
- TCP: Messages can be separated across packets.
- UDP: Every message encapsulated in one packet.
- Due to IPv4 being 32 bits long (that means 4,294,967,296 IPs only) and as a result of the increasing in number of devices joining networks. In mid-1994 NAT (Network Address Translators) was introduced. And it was supposed to be a temporary solution, but "there is nothing more permanent than a temporary solution"!
- If you want to have the service built on UDP only, you will face an issue regarding establishing the connection between the two sides, because the UDP package knows nothing about devices behind NAT!
- So there are some techniques and methods appeared to solve this issue ... STUN, TURN, and ICE (you can read about them on internet or Wikipedia) every solution has their pros and cons, and to get a reliable connection, you’re going to use one of them and others as failovers.
- If you’re going to use UDP, you should know that you’re doing a lot of things on your own, remember, UDP doesn’t have any kind of "Flow Control", "Congestion Control" or "Congestion Avoidance".
Ch4. Transport Layer Security (TLS).
- SSL and TLS are security protocols (asymmetric key cryptography) working in "Session" layer (the layer above TCP), although SSL and TLS technically are different protocols, but a lot of people still use them as equivalent, but they aren't! (actually SSL v3.0 was released in 1996, and as of 2014 the SSL 3.0 is considered insecure because of the "POODLE" attack, that means you should use TLS 1.2).
- TLS was designed to provide three essential things: 1. Encryption 2. Authentication 3. Integrity.
- Encryption - A mechanism to obfuscate what is sent from one computer to another.
- Authentication - A mechanism to verify the validity of provided identification material.
- Integrity - A mechanism to detect message tampering and forgery.
- In addition to traditional TCP 3-way handshake, TLS has also other handshakes. And this means more full roundtrip which means it will take more time! (HTTPS = more time! and more if not carefully managed!) The encrypted tunnel must be negotiated: the client and the server must agree on the version of the TLS protocol, choose the ciphersuite, and verify certificates if necessary.
- Performance of RSA (public-key cryptosystems) and ASE (symmetric-key cryptosystems) varies based on hardware, so you will need to make tests on your hardware to see the performance.
- Due to high cost of full TLS connection, new techniques have been invented to add ability to resume TLS sessions, so no need to full roundtrip.
- There are mainly two mechanism of TLS Session Resumption: 1. Session Identifiers 2. Session Tickets.
- Session Identifiers: as shown by its name it works as follows every client gets unique ID that has some information from first connection, and the server caches this ID, when the client makes a new connection it will do an abbreviated handshake instead of a full one. A lot of web browsers wait for the first TLS/HTTPS connection to take advantage of this feature if available. The downside of this mechanism is that all things done on the server side; The server does a lot of processing, caching and maintaining for every client, and this means a lot of CPU and RAM usage.
- Session Tickets: It is another mechanism to resume TLS connection. Unlike Session Identifiers, Session Tickets is a "Stateless Resumption", the server makes an encrypted record (ticket) that contains all information of client TLS session, and this record is stored by client. Next time the client makes a new connection it will just send this record. Although this record is stored on the client side, It is still safe because it is encrypted with a key known only by the server. (If you are using multiple load-balancers, make sure that all LBs use the same session key).
- The main point of TLS and encrypted connections is about "Trust", you must be confident you are connected to the right destination when you make a secure connection! if you aren't so, the encrypted connection is meaningless. So the web browser should have a way to make sure it's connected to the right destination, and it has a choice of three:
- Manually specified certificates: Every browser and operating system provides a mechanism for you to manually import any certificate you trust. How you obtain the certificate and verify its integrity is completely up to you.
- Certificate authorities: A certificate authority (CA) is a trusted third party that is trusted by both the subject (owner) of the certificate and the party relying upon the certificate.
- The browser and the operating system: Every operating system and most browsers ship with a list of well-known certificate authorities. Thus, you also trust the vendors of this software to provide and maintain a list of trusted parties.
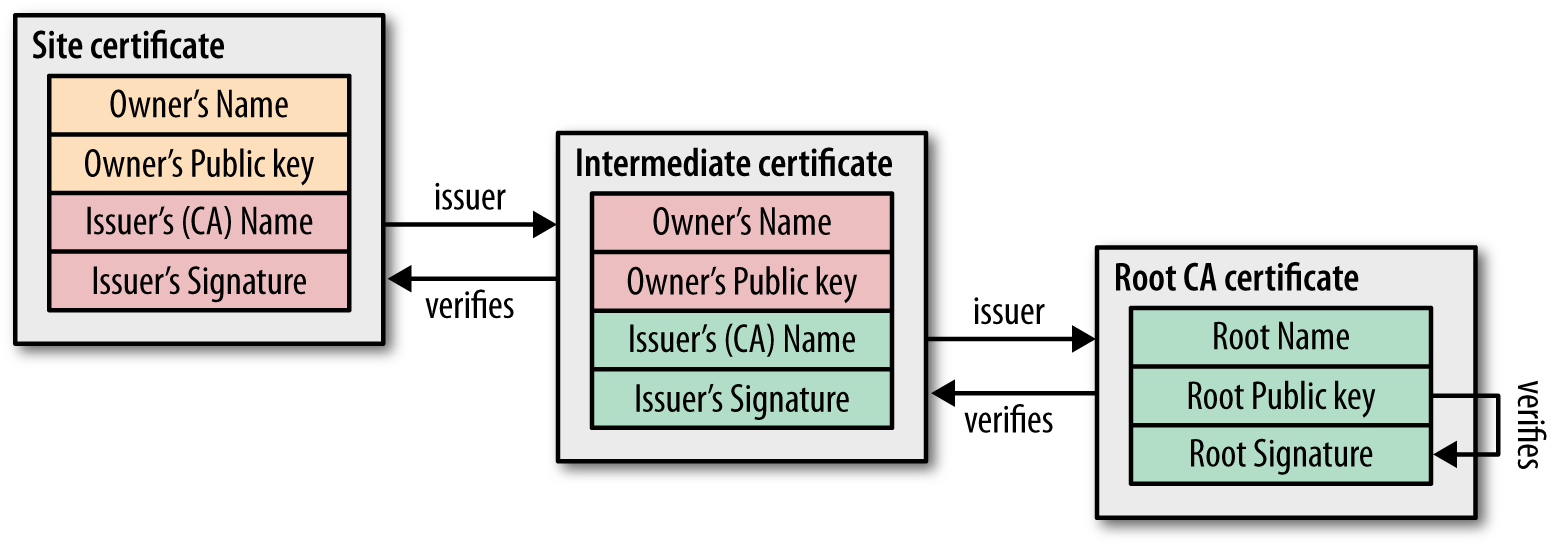
- Practically, Certificate Authority is the most commonly used method on the web, and CA actually is based on something called "Chain of Trust", Chain of Trust simply is when you trust "A" and this one give a trust for "B", then you can trust "B" based on your trust in "A" and this is what happens when "Root CAs" make certificates for any website that wants to use trusted SSL, and every system and browser are preloaded with all CAs they trust by default.
- The problem appears when you want to check: Does "A" still trust "B"? Is "B"'s certificate still valid? Hence there are many mechanisms that have been developed to check certificate revocation.
- Certificate Revocation List: CRL it's a list with all revoked certificates, and any browser needs to check the status of a certain certificate has to download the list and find the status of the certificate. the downside of this method is a long list means a long time to download, and there is no notification mechanism when the list is updated.
- Online Certificate Status Protocol: OCSP came to solve CRL problems, it allows browsers to query about a specific certificate, although this mechanism is faster and uses less bandwidth than CRL, it creates some other problems like that the CAs must create, maintain this service as well and make sure it's up and working as expected. Also this may slow down client navigation because it will be blocked till OCSP query is finished.
- In reality, CRL and OCSP complement each other and both are used.
- Due to TLS actually working over TCP, there is no need for additional modifications -or just small ones- in apps to use TLS. And for the same reason the same optimization for TCP will be suitable for TLS too; just small areas need to be checked with TLS like: size of TLS records, memory buffer, certificate size, and support for shortened handshake.
- As mentioned before, at the end TLS is an additional layer, and this came with a cost in processing and time, but by time and with evolution of software or mechanisms, this cost became smaller and smaller (and of course with right optimization makes the cost even lower).
- We already know that you can't make packets travel faster, but you can put your server closer to the user, hence CDNs (Content delivery network) appeared, its servers serve the user from the nearest place. CDN can serve the user directly (by caching the content), or working as proxy for origin servers.
- Maybe CDNs decrease latency for your users, but it can't remove all of latency, so you still need other optimizations for TLS, and the main one is "Session Resumption". Don’t assume "Session Caching" and "Session Ticket" are enabled by default, you need to double-check your server configuration; the good thing that "Session Caching" and "Session Ticket" aren't exclusive. And for best practice you should enable both of them: Session Caching is really easy to configure, but Session Caching may need more things to be checked:
- Servers with multiple processes or workers should use a shared session cache.
- Size of the shared session cache should be tuned to your levels of traffic.
- A session timeout period should be provided.
- In a multiserver setup, routing the same client IP, or the same TLS session ID, to the same server is one way to provide good session cache utilization.
- Where “sticky” load balancing is not an option, a shared cache should be used between different servers to provide good session cache utilization.
- Check and monitor your SSL/TLS session cache statistics for best performance.
- TLS record size plays an important role in HTTPS performance, but unfortunately there is no right answer for it. It depends on a lot of factors, but there’s an important rule that says: Small records incur overhead, large records incur latency. So make sure TLS record is not separated over multiple TCP packets.
- TLS compression is not just useless, but also detrimental! you should disable TLS compression because it will expose you to the risk of "CRIME" exploit, and on the other hand, it's not content aware. So it will compress contents that are already compressed like images and videos, and repeating the compression is a waste of resources for both server and client. Just make sure your server is configured to Gzip all text-based assets.
- Minimizing Certificate-chain length is another little known optimization, additional size of certificate-chain is one of the common mistakes; a lot of sites include unnecessary certificates specially "Certificate of Root CA" which is completely useless!
- Minimize the number of intermediate CAs. Ideally, your sent certificate chain should contain exactly two certificates: your site and the CA’s intermediary certificate; use this as a criteria in the selection of your CA. The third certificate, which is the CA root, should already be in the browser’s trusted root and hence should not be sent.
- It is not uncommon for many sites to include the root certificate of their CA in the chain, which is entirely unnecessary: if your browser does not already have the certificate in its trust store, then it won’t be trusted, and including the root certificate won’t change that.
- A carefully managed certificate chain can be as low as 2 or 3 KB in size, while providing all the necessary information to the browser to avoid unnecessary roundtrips or out-of-band requests for the certificates themselves. Optimizing your TLS handshake mitigates a critical performance bottleneck, since every new TLS connection is subject to its overhead.
- One of the steps of a secure connection is to check a certificate’s status; is it still valid or revoked? Actually this step is widely different from one browser to another. However, one of the mechanisms to shorten this process called "OCSP Stapling", with OCSP Stapling the server can include the OCSP response from the CA to its certificate chain, this allows the browser to skip extra requests of certificate verification thus decreasing the time of establishing a connection.
- Another option with TLS is "HTTP Strict Transport Security", HSTS simply a HTTP header tells the browser to use HTTPS by default, this means the browser will automatically send HTTPS requests, so it eliminates unnecessary redirection from HTTP to HTTPS (This is useful when a website is using HTTPS for all connections).
Performance Checklist:
- Get best performance from TCP.
- Upgrade TLS libraries to latest release, and (re)build servers against them.
- Enable and configure session caching and stateless resumption.
- Monitor your session caching hit rates and adjust configuration accordingly.
- Terminate TLS sessions closer to the user to minimize roundtrip latencies.
- Configure your TLS record size to fit into a single TCP segment.
- Ensure that your certificate chain does not overflow the initial congestion window.
- Remove unnecessary certificates from your chain; minimize the depth.
- Disable TLS compression on your server.
- Configure SNI support on your server.
- Configure OCSP stapling on your server.
- Append HTTP Strict Transport Security header.